We are excited to announce that version 0.34 of the HashiCorp Terraform language server, bundled with version 2.32 of the Terraform extension for Visual Studio Code, is now available. This latest iteration brings significant reductions in initial work and memory usage when opening workspaces. Additionally, version 0.34 of the language server introduces parallel loading of Terraform language constructs, which enables instantaneous autocompletion. This blog post highlights the new enhancements and the results of the improvements.
Performance with large Terraform workspaces
The Terraform language server provides IDE features in LSP-compatible editors like Visual Studio Code, Sublime Text, Neovim, and others. With previous versions of the Terraform language server, the initial loading experience of large and/or complex Terraform configurations could be time-consuming and resource-intensive. That’s because when opening the editor, the Terraform language server did a lot of work in the background to understand the code being worked on.
Its indexing process finds all the Terraform files and modules in the current working directory, parses them, and builds an understanding of all the interdependencies and references. It holds this information inside an in-memory database, which is updated as files are changed. If a user opened a directory with many hundreds of folders and files, it would consume more CPU and memory than they expected.
Improved language server performance
Improving the efficiency and performance of the Terraform language server has been a frequent request from the Terraform community. To address the issue, we separated the LSP language features for several Terraform constructs:
- Modules: This feature handles everything related to *.tf and *.tf.json files.
- Root modules: This feature handles everything related to provider and module installation and lock files.
- Variables: This handles everything related to *.tfvars and *.tfvars.json files.
Splitting the existing language-related functionality into multiple, smaller, self-contained language features lets the server process the work related to the different constructs in parallel. At the same time, we were able to reduce the amount of work a feature does at startup and shift the work to a user's first interaction with a file.
In addition, the language server now parses and decodes only the files a user is currently working with, instead of fetching the provider and module schemas for the entire workspace at startup. The indexing process begins only when a user later opens a file in a particular folder.
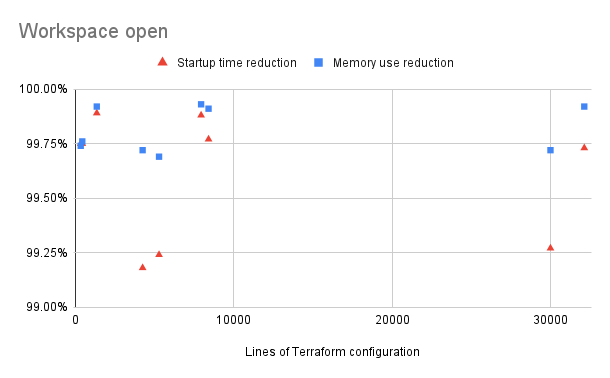
This new process brings a significant reduction (up to 99.75%) in memory usage and startup time when opening a workspace. For example, we measured a workspace with 5,296 lines of code that previously took 450ms to open and consumed 523 MB of memory. After updating to the 0.34 language server and the 2.32 VS Code extension, open-time dropped to 1.4ms and only 1.6 MB of memory was consumed. The new process also reduces memory use and cuts startup time when opening files within a workspace. That’s because instead of keeping the schemas for everything in memory, Terraform now has only the schemas for the currently open directory.
Summary and resources
Enhancements to the HashiCorp Terraform extension for Visual Studio Code and Terraform language server are available today. If you've previously encountered problems with language server performance but have not yet tried these updates, we encourage you to check them out and share any bugs or enhancement requests with us via GitHub issues. Learn more by reading the LS state & performance refactoring pull request details on GitHub.
If you are currently using Terraform Community Edition or are completely new to Terraform, sign up for HCP Terraform and get started using the free offering today.
from HashiCorp Blog https://ift.tt/9TJa78i
via IFTTT
No comments:
Post a Comment